
How Uber Built Big Data System — From a Few TBs to 350 Petabytes with Sub-Hour Latency

Uber built Big Data system across three architectural generations, moving from a Vertica warehouse to a Hadoop data lake, and ultimately to Apache Hudi — a technology created by Uber itself to solve the challenge of upserts and incremental processing at the hundreds-of-petabytes scale. This journey isn’t just about choosing the right tools, but about recognizing hard limits and having the courage to re-architect before the system collapses.
What is Uber’s Big Data Platform?
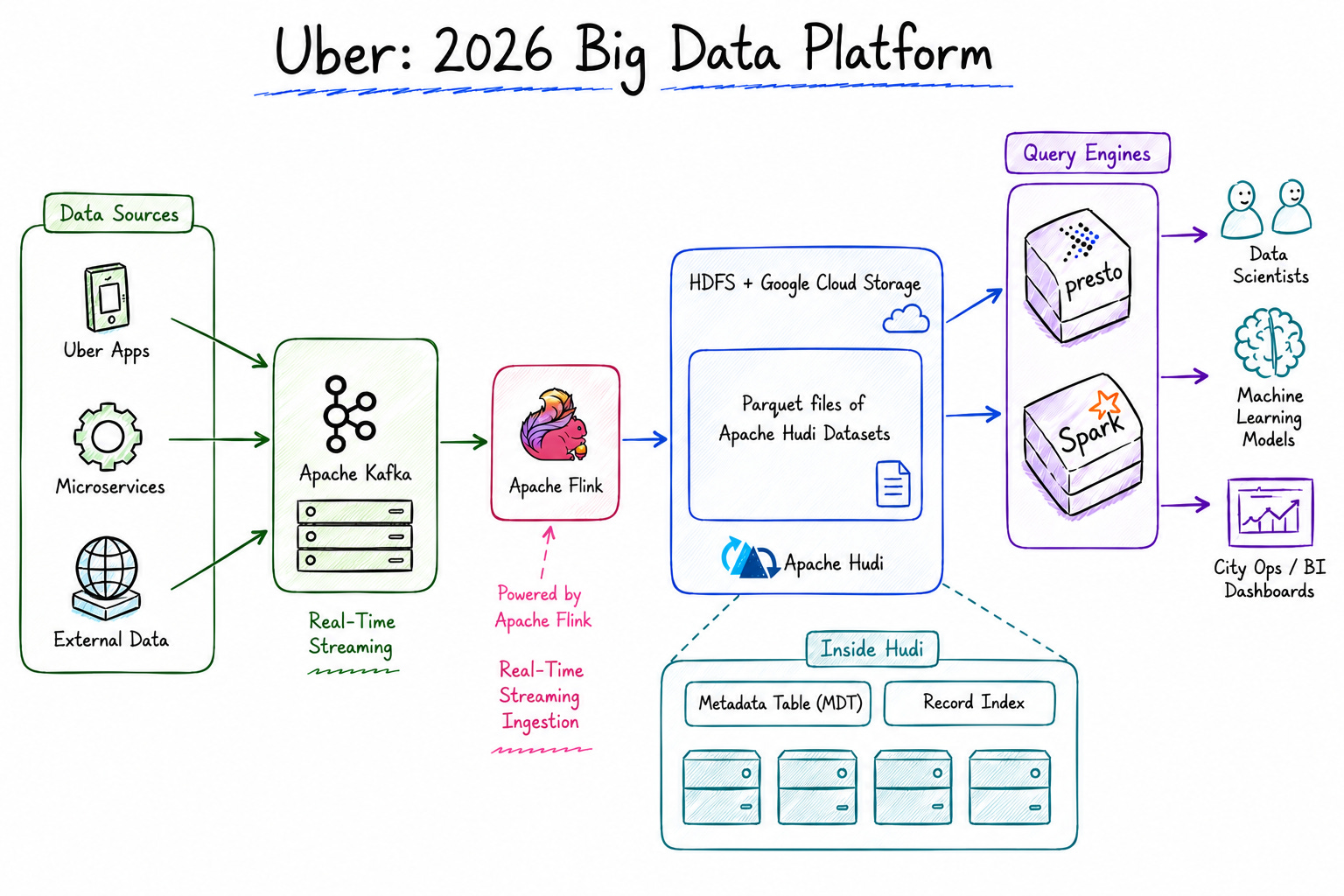
Uber’s Big Data Platform is a distributed data infrastructure that processes over 350 petabytes of data, ingests 6 trillion rows daily from hundreds of microservices, and serves 4 million analytical queries per week with sub-30-minute latency — built on HDFS, Apache Hudi, Apache Spark, and Presto.
Every ride you book on Uber leaves a digital footprint. Not just one row of data — but dozens: pickup location, dropoff location, driver rating, ETA calculation, surge pricing events, payment processing, and trip status updates. And that is just one ride, for one user, in one city.
Multiply that by millions of daily rides across hundreds of cities, add Uber Eats, Uber Freight, and constantly launching new features — the result is 6 trillion rows ingested every day, totaling 350 petabytes of storage.
The central question: When a company grows at Uber’s breakneck speed, how do you design a data system so it doesn’t get crushed by its own data?
Uber’s journey is a story of continuously recognizing the limits of old architectures and bravely re-architecting from scratch — not once, but three times.
Why Uber Needed Non-Standard Big Data?
Uber’s Unique Data Characteristics
To understand why Uber had to build what the rest of the industry didn’t have, you need to understand how Uber’s data is different.
Most companies’ data is append-only: logs are written and never modified. But Uber’s data is inherently mutable. A trip does not end when the rider steps out of the car:
A driver rating might be updated the next day.
A fare might be adjusted days later due to a dispute.
A backfill might occur weeks later due to business rule changes.
This is the crux of why standard industry solutions were insufficient. While the rest of the industry was building append-only data lakes, Uber fundamentally needed something else.
Furthermore, Uber serves three user groups with completely different needs — simultaneously, on a single platform:
City Ops (thousands of users): Need simple, near-real-time SQL to make daily operational decisions.
Data Scientists/Analysts (hundreds of users): Need full datasets for long-term modeling and forecasting.
Engineering Teams (hundreds of users): Need data for automated pipelines such as fraud detection and driver onboarding.
The Scale of the Problem (as of 2024–2025)
To provide a glimpse of the destination before diving into the journey:
19,500 managed Hudi datasets
6 trillion rows ingested daily / 3 million new data files daily
350 petabytes across HDFS and Google Cloud Storage
350,000 commits daily / 70,000 daily table service operations
4 million analytical queries/week via Presto and Spark
Generation 1: “Warehouse-as-Lake” and Its Costs
Initial Architecture (Pre-2014)
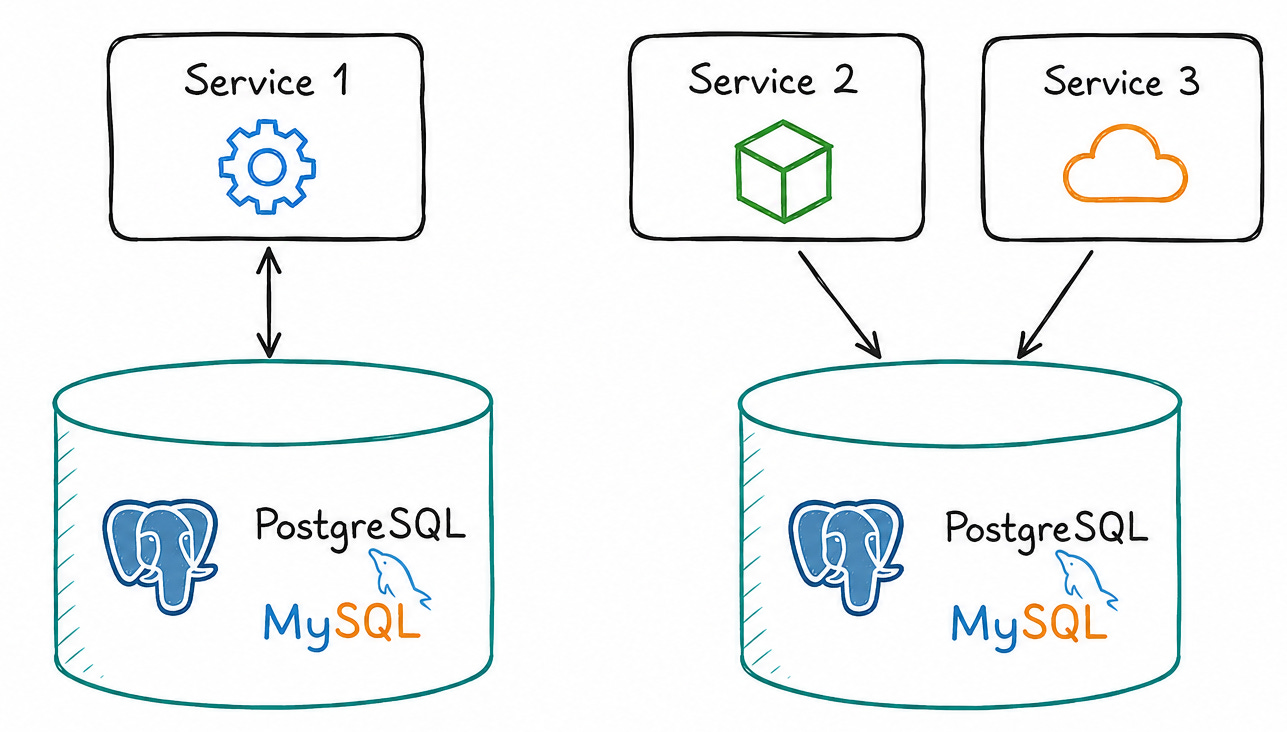
Before 2014, Uber’s data was scattered across various OLTP databases — MySQL, PostgreSQL. Any engineer needing data had to know exactly which database to access and write custom code to join data from multiple sources. There was no global view. No centralized access. The total volume was just a few terabytes — small enough that access latency was usually under a minute.
This model worked when Uber was small. But as the business began to scale exponentially — adding cities, product lines, and engineers — the lack of consistency became a disaster.
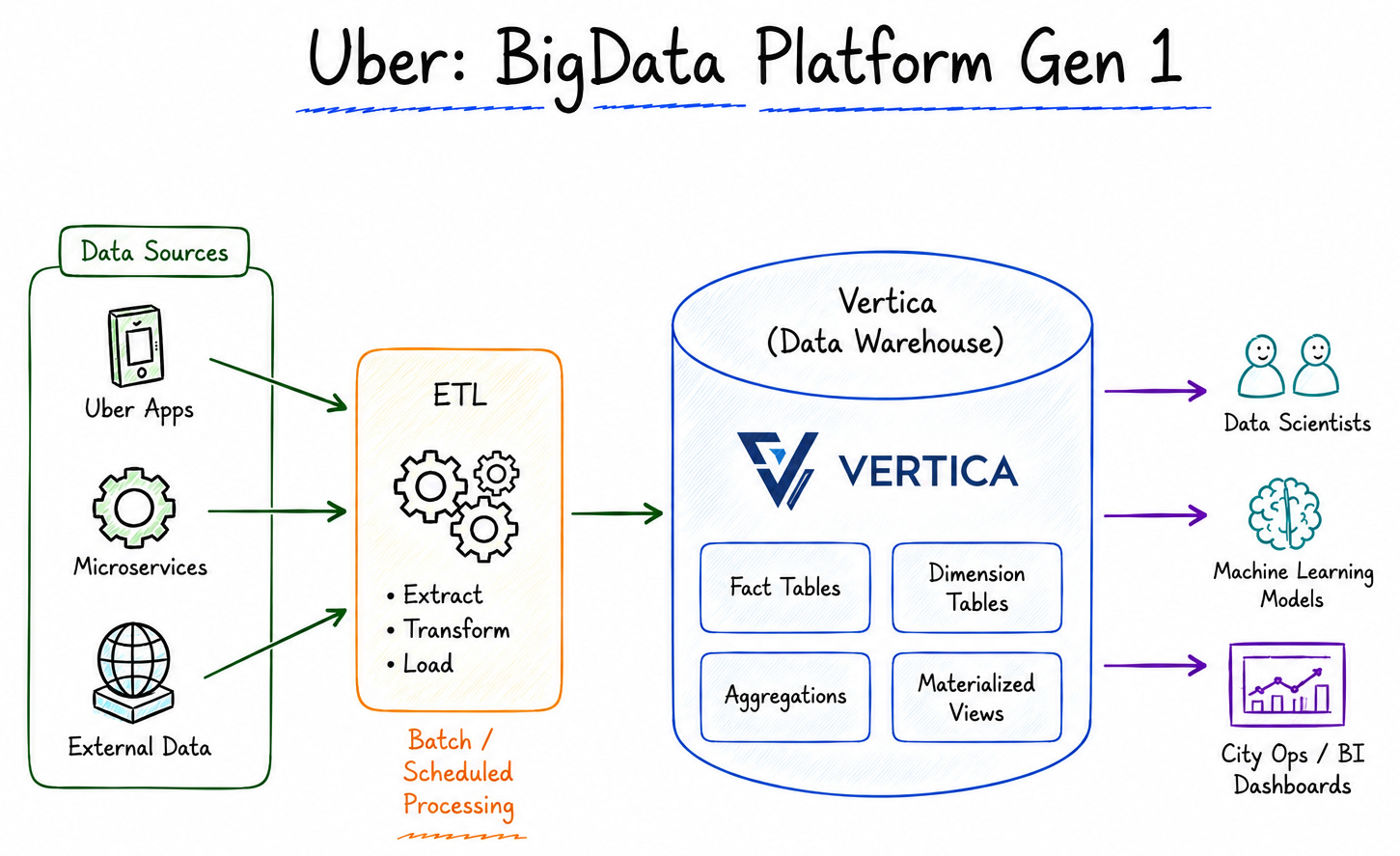
Gen 1: Data Warehouse with Vertica
The first solution was building a centralized data warehouse. Uber chose Vertica for its columnar design, which was fast and scalable compared to other options at the time.
The architecture was simple: multiple ad hoc ETL jobs copied data from various sources (AWS S3, OLTP databases, service logs) into Vertica. SQL was standardized as the single interface.
The initial result was a massive success. For the first time, everyone in the company had a global view — a single place to query all data. Hundreds of new users emerged. City operators started using SQL for decision-making. New teams formed around data: machine learning, experimentation.
When Success Becomes a Burden
However, this popularity was also the beginning of the problem. With more users and more data, the warehouse began revealing fundamental limitations:
Schema drift was the first issue. The source data was primarily in JSON — a very flexible format without strict schema enforcement. Because of this, if a team quietly changed the structure of the data they sent (e.g., renaming a column or changing a number to a string), downstream ETL pipelines programmed for the old structure wouldn’t understand it. Consequently, the entire processing system would break without warning.
Duplicate ingestion complicated everything. Because ETL jobs were ad hoc — each team wrote their own — the same dataset could be ingested multiple times with different transformations. Result: multiple versions of the “truth” co-existed in the warehouse, and nobody knew which one was correct.
Scaling costs became irrational. The warehouse wasn’t horizontally scalable. As data grew, Uber had to delete old data to make room for new data. An analytics system that couldn’t retain history.
The warehouse became a single point of failure. Everything — raw ingestion, transformation, serving — ran on Vertica. This was no longer a data warehouse; it was a data monolith.
Generation 2: Hadoop Data Lake and the Lesson of Incremental Processing
Re-architecting Around the Hadoop Ecosystem
The core decision of Gen 2 was radical: completely separate raw ingestion from data modeling.
The design principles were simple but crucial:
Raw data enters Hadoop once, with no transformation during ingestion (EL, not ETL).
All transformations occur inside Hadoop via horizontally scalable batch jobs.
Only processed data tables are pushed to Vertica — for city ops requiring fast SQL
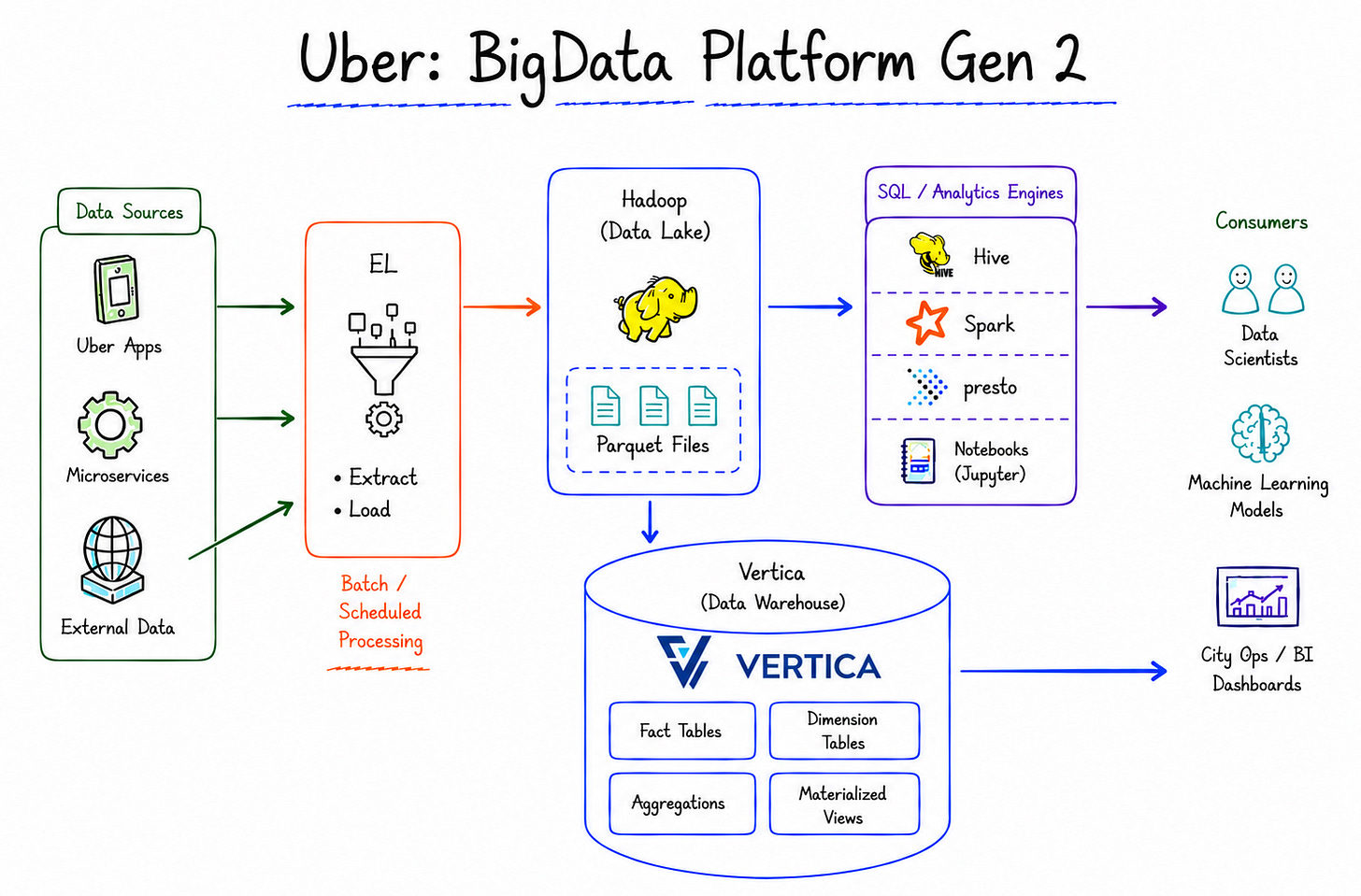
Uber: BigData Platform Gen 2
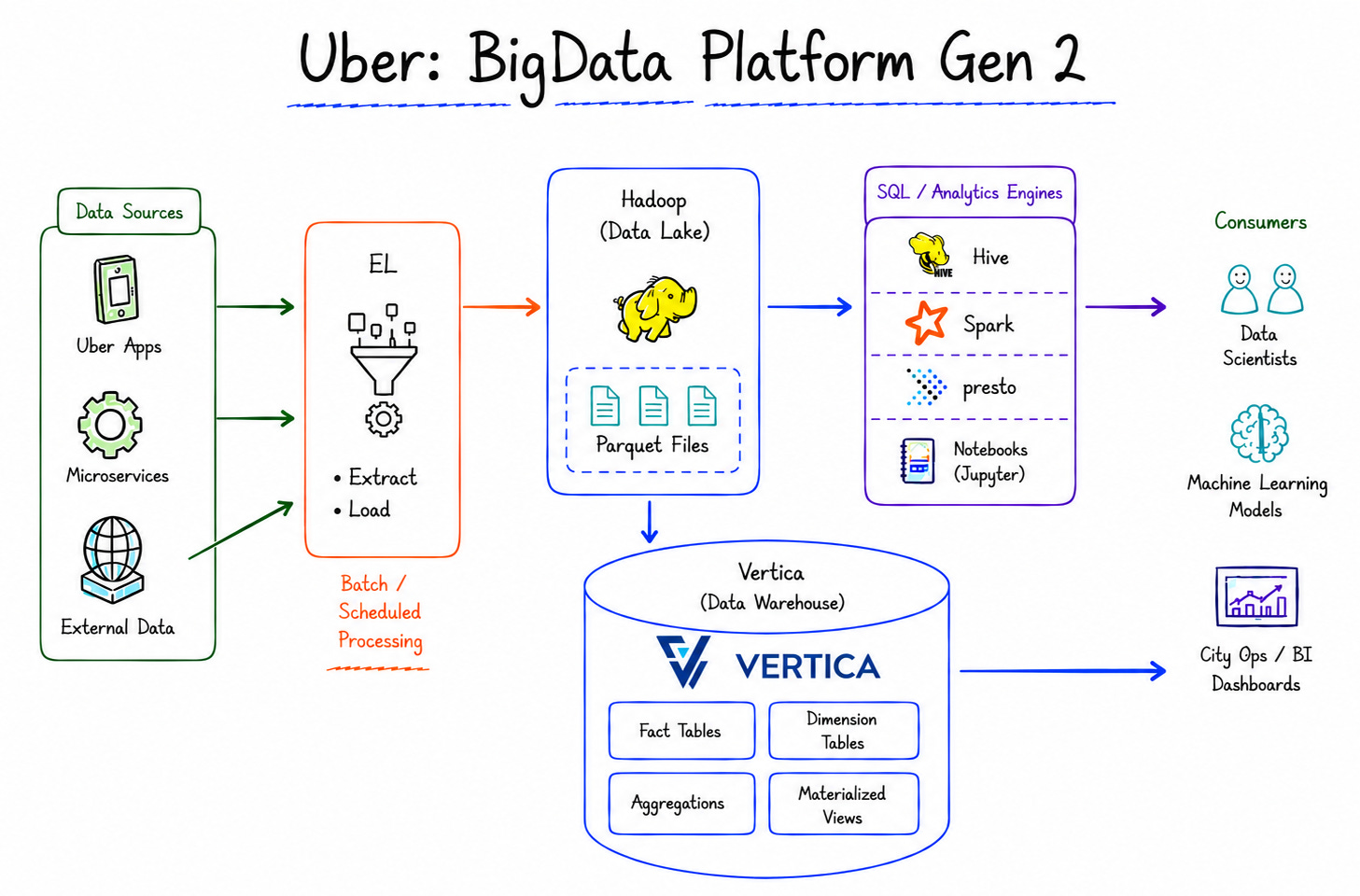
Technology Stack and Rationale
Uber built Gen 2 on four main technologies, each serving a different use case:
Apache Parquet: A columnar storage format enabling efficient data compression and faster querying. Integrates seamlessly with Spark.
Apache Presto: Serves instant ad-hoc queries — for cases where users need results in seconds rather than hours.
Apache Spark: Enables the programming of complex data pipelines, supporting both SQL and non-SQL queries.
Apache Hive: The “workhorse” specializing in processing massive batch queries.
(Note: Kafka was not formalized in Gen 2. Ingestion still used batch jobs reading from upstream OLTP datastores. Kafka officially emerged in Gen 3 as a formal handoff mechanism.)
Results Achieved
The results exceeded expectations. With tens of petabytes, 10,000 vcores, and 100,000 batch jobs per day — HDFS became Uber’s first centralized source-of-truth. Horizontal scalability was finally achieved at every layer.
The New Limit: The Snapshot-Based Ingestion Problem
However, Gen 2 brought an inherent limitation: snapshot-based ingestion.
Because HDFS and Parquet do not support in-place updates, every time an ingestion job ran, the system had to recreate an entire snapshot of the dataset. The consequences were:
Data latency reached up to 24 hours. New data was only accessible after each daily run. For a real-time business like Uber, this latency was unacceptable.
Irrational waste of compute resources. Suppose a table had 100TB of data, but only 100GB changed daily — the ingestion job still had to scan and reprocess the entire 100TB, using over 1,000 Spark executors and taking more than 20 hours to complete. Over 99.9% of compute resources were wasted.
HDFS NameNode Bottleneck. Too many small files generated from ad-hoc jobs began overloading the HDFS NameNode — the core component responsible for managing the metadata of the entire filesystem.
ETL pipelines also operated on a snapshot basis. Not just raw ingestion — modeling jobs also had to recreate entire derived tables during every run. The entire data pipeline operated inefficiently from top to bottom.
By early 2017, with over 100 Petabytes of data stored in HDFS and 100,000 vcores, the system had hit its scalability limits. Uber realized they needed a completely different approach.
Apache Hudi is Born: When There is No Solution, Build It
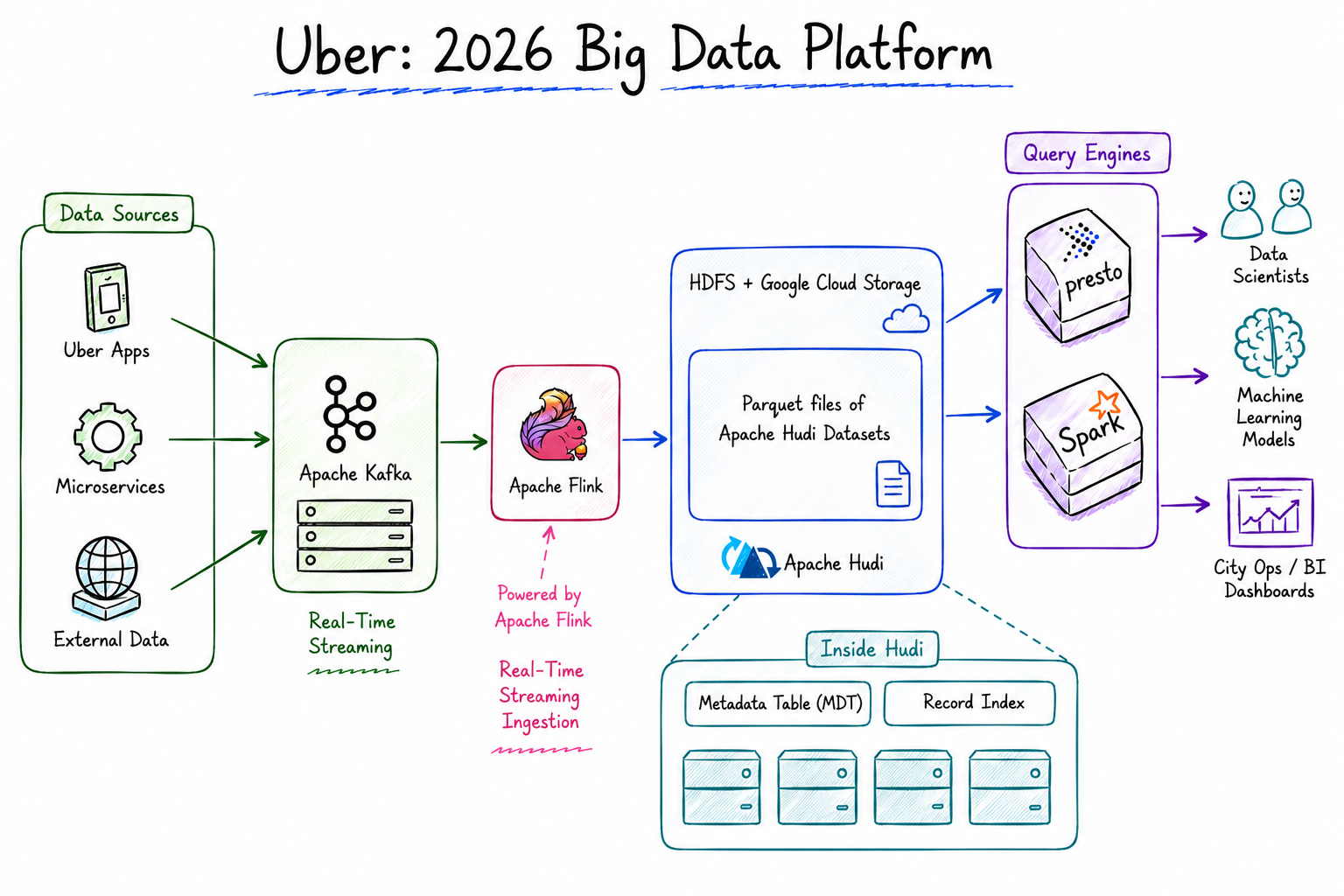
A Problem with No Market Solution
Uber needed three things simultaneously:
Upsert operations on HDFS/Parquet — which is append-only storage.
Incremental reads — reading only changed data since the last checkpoint, rather than scanning the entire table.
Sub-hour latency instead of 24 hours.
There was no technology on the market at the time (early 2017) that could simultaneously meet all three requirements. This wasn’t a case of Uber “not wanting to buy” an off-the-shelf solution — there was truly a massive gap in the data technology ecosystem. Uber was forced to build it themselves.
How Hudi Works
Hadoop Upserts anD Incremental (Hudi) is a Spark library that creates an abstraction layer over HDFS and Parquet — adding capabilities that these two technologies lack.
The central mechanism is Copy-on-Write (CoW): when a record needs an update, Hudi rewrites the entire Parquet file containing that record with the new value. Write costs increase, but in return, reading remains extremely fast because there is no complex merge logic required.
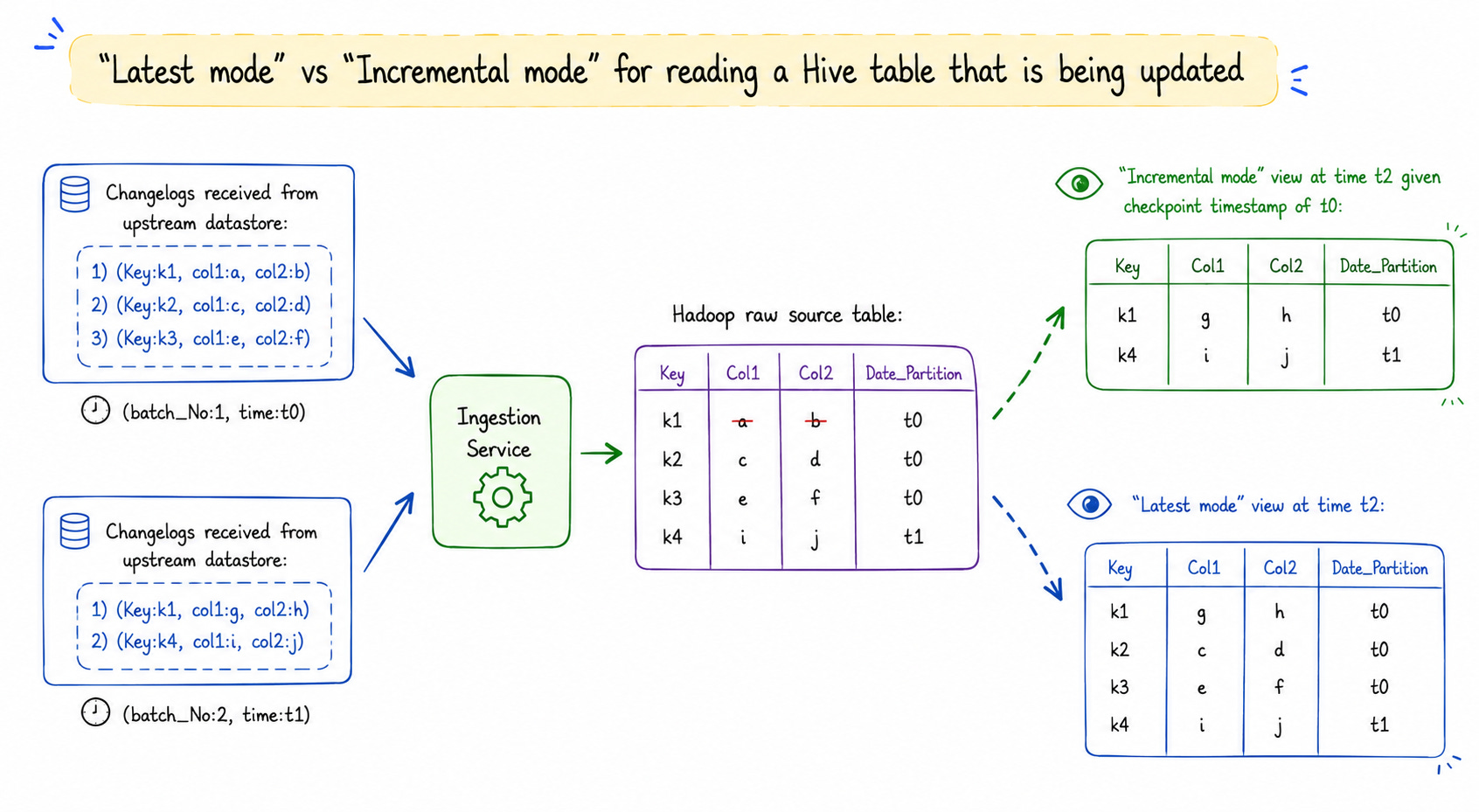
Hudi provides two ways to read data for every table:
Latest mode view (or Snapshot view): Returns a holistic view of the entire table at a point in time — the latest value for every record. Used when the full dataset is needed.
Incremental mode view: Returns only records inserted or updated since a specific checkpoint timestamp. ETL jobs only need to pass the timestamp of their last run — no further scanning is needed.
Result: Data latency dropped from 24 hours to under 1 hour. With corresponding compute savings since there was no longer a need to scan entire tables every run.
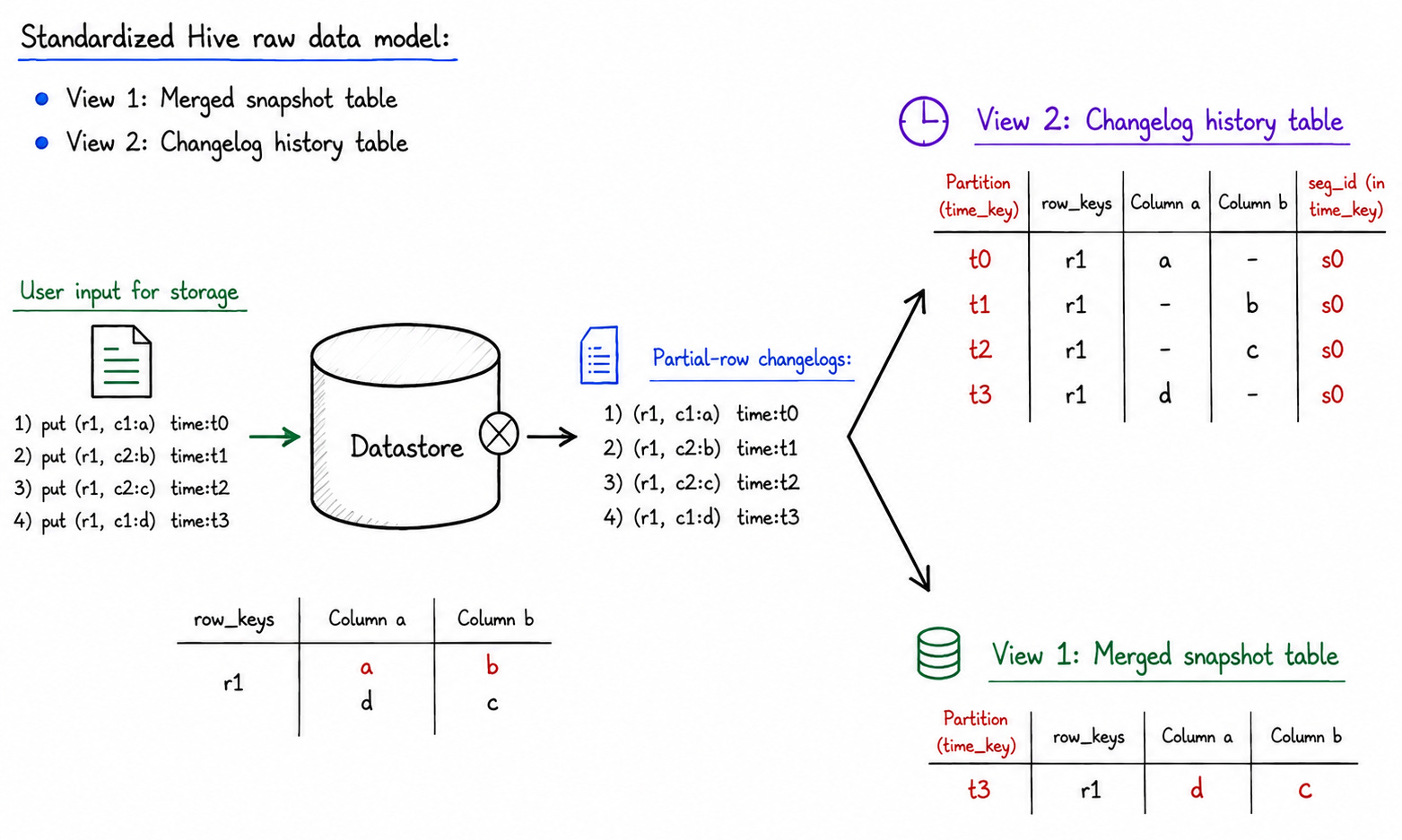
Standardized Data Model: Two Types of Tables for All Raw Data
Uber also standardized how raw data is organized in Hadoop into two primary table types:
Changelog History Table: Stores the entire history of changelogs received from upstream systems. This table can be sparse — because upstream systems sometimes only send partial rows corresponding to the newly changed columns.
Merged Snapshot Table: Provides a unified and up-to-date view of the source data — always ensuring all columns are present for a given key, regardless of how complex the update history was.
Why both are maintained: The Changelog table might be missing data in some columns (since the source system doesn’t resend the entire row on every update). Conversely, the Snapshot table is the most complete version, used when joins or queries on full entity attributes are required.
Marmaray: The Ingestion Platform of Gen 3
Hudi solved the problem at the storage layer. But the question remained: what system would handle feeding data into Hudi?
To answer this, Uber built Marmaray — a generic data ingestion platform. Marmaray operates on a mini-batch model running every 10–15 minutes, consuming changelogs from Apache Kafka (at this point, Kafka was officially chosen as the standard interface between the Storage and Big Data teams), and then applying these changes to Hadoop via Hudi.
At the Kafka level, every upstream event is encoded in Avro format, accompanied by standardized metadata headers, including: timestamp, row key, version, data center information, and the originating server. This mechanism creates a clear and strict contract between the producer and the consumer.
Ingestion jobs are scheduled to run every 10–15 minutes, plus enough headroom to handle 1–2 failed runs. Thanks to this, Uber achieved a 30-minute raw data latency end-to-end.
Uber established an unbreakable rule: absolutely no data transformation during ingestion. Marmaray is positioned as an EL (Extract-Load) platform, not ETL (Extract-Transform-Load). Raw data must remain 100% intact upon entering Hadoop. All data transformations are only allowed inside Hadoop after the data has successfully landed. This design offers a massive advantage: when data processing errors occur, engineers simply re-run the transformation step without having to re-ingest all the data from the source.
Evolution: From Marmaray to Apache Flink (IngestionNext)
While Marmaray and its mini-batch model created a giant leap by reducing data latency to 30 minutes, it eventually revealed new limits. For highly time-sensitive workloads, 30 minutes is still too long to wait. Furthermore, scheduling and continuously maintaining tens of thousands of periodic batch jobs created immense pressure on compute resources due to scheduling overhead.
To fundamentally solve this problem, Uber launched the IngestionNext project — marking a major shift from Marmaray (Spark) to Apache Flink. Instead of waiting to batch data, the new platform uses streaming-native ingestion. The tight integration between Flink and Hudi enables 24/7 continuous data ingestion, pushing data latency down from 30 minutes to under 15 minutes, while significantly cutting hardware resource consumption.
Comparison of the 3 Architectural Generations

Hudi at Trillion-Record Scale: 3 Engineering Breakthroughs
The Gen 3 architecture successfully solved the latency and upsert challenges at the tens-of-petabytes scale. However, as the system continued scaling to tens of thousands of datasets with hundreds of billions of rows per table, the core architecture of Hudi itself had to be re-engineered. This is the most complex and specialized technical aspect — encompassing three innovations that Uber had to invent, because open-source Hudi could no longer keep up.
Workload Classification at True Scale (2024)
Before diving into the breakthroughs, it is essential to understand that Uber divides its 19,500 datasets into four workload classes:
Append-Only Datasets (11,200 tables): The group with the largest volume, primarily using bulk insert. Key metric: ingestion speed.
Upsert-Heavy Datasets (4,400 tables): Represents mutable business states with extremely high update frequency. Key metric: write throughput and commit speed.
Derived Datasets (1,600 tables): Serves ETL and Machine Learning pipelines, utilizing incremental reads from source tables. Key metric: correctness and schema evolution.
Realtime Flink-Native Streaming (500 tables): Processed via direct streams using Flink with a Service Level Objective (SLO) for data freshness under 15 minutes. Key metric: latency and throughput.
Additionally, an asynchronous Table Services Platform runs 70,000 operations daily — compaction, clean, clustering, file stitching — without blocking the ingestion process.
Breakthrough 1: Metadata Table (MDT) — Solving the File Listing Problem
The core problem: When you have tens of thousands of datasets, each with thousands of partitions, and each partition containing millions of files — even the simplest operation like listing files in a directory becomes a bottleneck.
The HDFS NameNode — the core component managing all filesystem metadata — was completely overwhelmed by continuous file listing requests from readers/writers, table management services, and query engines. This issue not only severely degraded performance but also threatened the stability of the entire system.
The Solution — Metadata Table (MDT): MDT is a key-value store managed directly by Hudi. It uses HFile as its foundational format (based on the SSTable structure for lightning-fast indexing), specifically designed to store:
File listing metadata for every partition.
Column-level statistics (min/max values per Parquet file) — used for query pruning to eliminate scanning unnecessary data.
Bloom filters — facilitating fast record location lookups during upserts.
Instead of having to scan the entire filesystem (filesystem scan), every operation now only requires a single key-value lookup. The algorithmic complexity drastically dropped from O(n) linear scans down to just O(1) per lookup.
Production impact: MDT has been successfully deployed across more than 90% of datasets. The bottleneck at the HDFS NameNode has been completely eliminated, even at extreme scale.
Breakthrough 2: Record Index (RI) — Upserts on Trillion-Row Tables
The core problem: To perform an upsert, the system must precisely identify which Parquet file contains the record to be updated. At a smaller data scale, methods like Bloom filters and file scans suffice. However, as the system scales to hundreds of billions of rows, this problem becomes vastly more complex.
Initially, Uber experimented with using HBase as an external index. While powerful, it came with high operational complexity: the system relied on an external service requiring separate maintenance, creating a potential single point of failure.
The Solution — Record Index (RI): RI is an HFile-backed data structure residing inside the MDT — eliminating the need for external servers. It maps each record key to a file group, enabling lookups with an O(1) complexity.
Real production figures:
3,600 large tables use RI
The largest tables exceed 300 billion rows: indexes are sharded into 10,000 HFiles, with parallelized lookups via thousands of executors.
Lookup latency: 1–2ms per record key
Initialization of a 300B-row table: ~7 hours using ~4,000 executors
Roadmap: Scaling to 1.2 trillion row tables
Without the Record Index, upsert-driven pipelines at the trillion-row scale simply would not function. It is a prerequisite, not just an optimization.
Breakthrough 3: Multi-Data-Center Reliability
Requirements: Mission-critical datasets — powering mobility, delivery, maps, and commerce — must remain highly available and consistent across multiple regions. An outage in a single region must not be allowed to bring down the entire analytics platform.
Architecture:
Utilizing a model of a primary dataset alongside a replicated secondary dataset located in a different geographical region.
Hudi’s commit timeline and atomic operations ensure that all write operations — whether streaming, batch, or table management services — are safely propagated to the secondary region.
Validation & consistency-checking tools ensure data between regions remains perfectly aligned.
Table availability service continuously monitors regional health and automatically promotes the secondary replica to primary in the event of a disruption.
Intelligent query routing: Queries from Presto and Spark are automatically routed to the closest or healthiest region — reducing global query latency and balancing compute load.
Besides ensuring multi-DC reliability, Uber has also successfully migrated part of its data lake to Google Cloud Storage (GCS) with zero downtime. Cloud storage provides dynamic scaling while fully preserving Hudi’s consistency guarantees and robust replication mechanisms.
FAQ
Q: What technology does Uber use for its Big Data platform?
Uber uses Apache Hudi running on HDFS as its primary storage engine, combined with Apache Spark and Presto for query operations. For data transport, the system utilizes Kafka as its data streaming platform. For the ingestion platform, Uber initially used the internal tool Marmaray (based on a mini-batch processing model), but later aggressively shifted to Apache Flink to support real-time streaming ingestion. Notably, Apache Hudi is a technology invented by Uber itself to fundamentally solve the challenges of upserts and incremental processing on the Data Lake.
Q: What is Apache Hudi and why did Uber create it?
Apache Hudi (Hadoop Upserts anD Incremental) is a data lake storage engine that supports upsert, delete, and incremental reads on HDFS. Uber created it in 2016–2017 because there was no technology on the market capable of handling mutable data updates at petabyte scale with sub-hour latency.
Q: Why didn’t Uber use a traditional data warehouse like Vertica at scale?
Vertica is not horizontally scalable and does not support strict schema enforcement for JSON data. As data grew to tens of petabytes, the storage and compute costs of a warehouse became unfeasible. Uber had to migrate to a Hadoop data lake to separate ingestion from serving.
Q: How does Uber solve the data freshness problem?
Uber used Hudi incremental ingestion via Marmaray, running mini-batches every 10–15 minutes, which reduced data latency from 24 hours down to 30 minutes. Uber is currently transitioning to Flink-native streaming to achieve sub-15-minute freshness for its most critical datasets.
Q: How does the Record Index in Apache Hudi work?
The Record Index is an HFile-backed structure stored within the Metadata Table that maps record keys to file groups with O(1) lookups, requiring no external servers like HBase. Lookup latency is merely 1–2ms per record, enabling efficient upserts on tables with over 300 billion rows.
Conclusion
Uber’s journey through three generations of architecture — from a Vertica warehouse to a Hadoop snapshot lake and finally to a Hudi incremental platform — isn’t a story of choosing the right tool from the start. Nobody can choose perfectly from day one when scale changes exponentially.
This is a story about recognizing limits at the right moment and bravely re-architecting instead of applying temporary patches. Gen 2 succeeded not because it was perfect — but because it was horizontally scalable enough to buy Uber the time to build Gen 3 properly. Gen 3 succeeded not because Hudi is the best tool in the world — but because Uber accurately understood the nature of its data (mutable, not append-only) and built the right abstraction for it.
Uber didn’t just build a Big Data platform — they redefined how a data lake should operate with mutable data at extreme scale. And that contribution, through Apache Hudi, is now benefiting 65% of the Fortune 500 and the entire industry.
References: